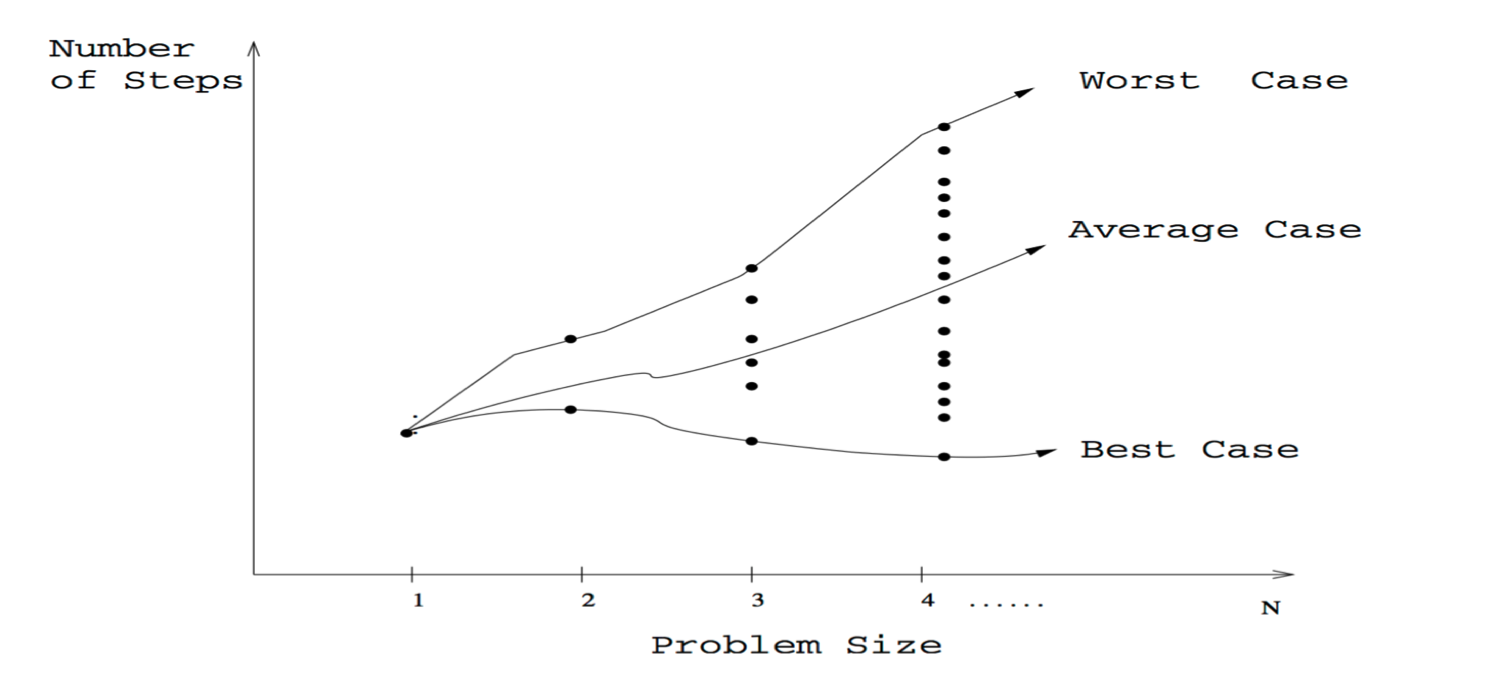
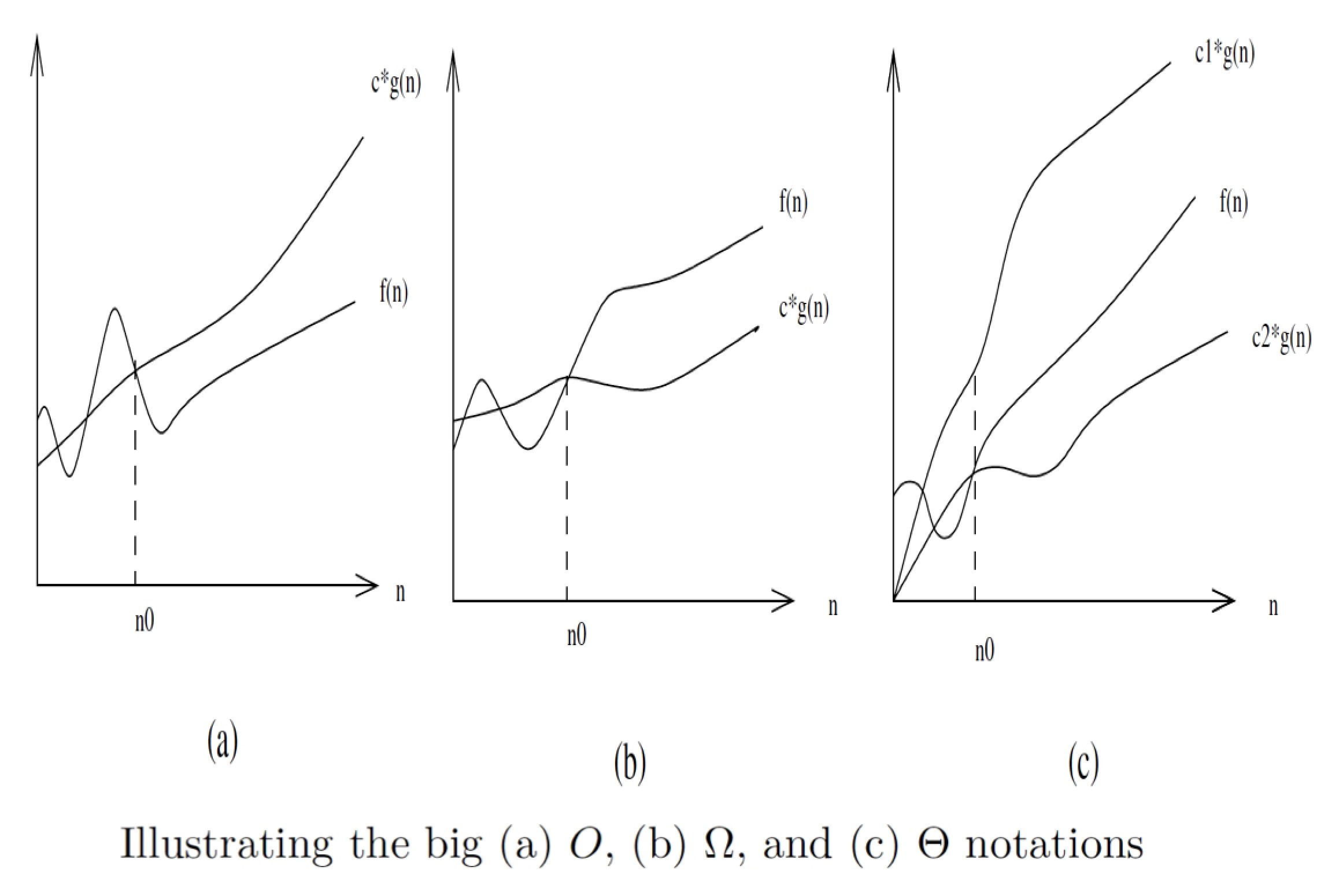
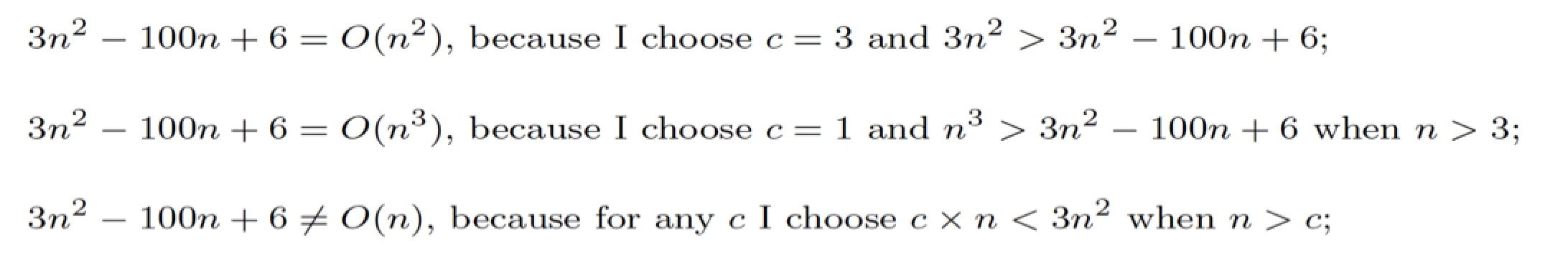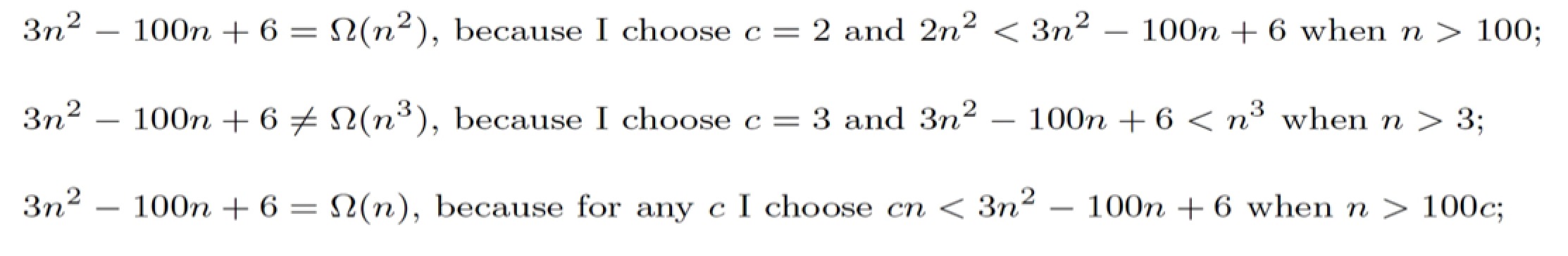What is Angular JS?
The official AngularJS introduction describes AngularJS as a:
“client-side technology, written entirely in JavaScript. It works with the long-established technologies of the web (HTML, CSS, and JavaScript) to make the development of web apps easier and faster than ever before.”
In 2010, Miško Hevery was working at Google on a project called Feedback. Based on Google Web Toolkit (GWT), the Feedback project was reaching more than 17.000 lines of code and the team was not satisfied with their productivity. Because of that, Miško made a bet with his manager that he could rewrite the project in 2 weeks using his framework. After 3 weeks and only 1.500 lines of code, he delivered the project.
The name of the framework was given by Adam Abrons, and it was inspired by the angle brackets of the HTML elements.
Why use Angular JS?
The AngularJS team describes it as a “structural framework for dynamic web apps.” AngularJS makes it incredibly easy to build complex web applications. It is a framework that is primarily used to build single-page web applications.
A Single-page applications where an initial HTML document is sent to the browser, but user interactions lead to Ajax requests for small fragments of HTML or data inserted into the existing set of elements being displayed to the user. The initial HTML document is never reloaded or replaced, and the user can continue to interact with the existing HTML while the Ajax requests are being performed asynchronously, even if that just means seeing a “data loading” message.
AngularJS takes care of the concerns of the modern web applications, such as:
Separation of application logic, data models, controller and views (Model-View-Controller), Bi-directional Data Binding, Dependency injection, routing, Testing etc.
When Not to Use AngularJS?
AngularJS app is generally data-driven.It’s also a good choice if you are writing an application which interacts with lots of Rest web services.
If your application needs lot of DOM manipulations and data is not much important then a library like JQuery many be a perfect fit. AngularJS is also not a good choice for web application for game or where lot of graphics is involved.
Understand MVC in Angular Context
Server Side MVC
When you see MVC on server side, basically model represent a domain object, a controller represent a servlet or web service and view nothing but the presentation model which have data required to render on the UI which may be different from domain object.
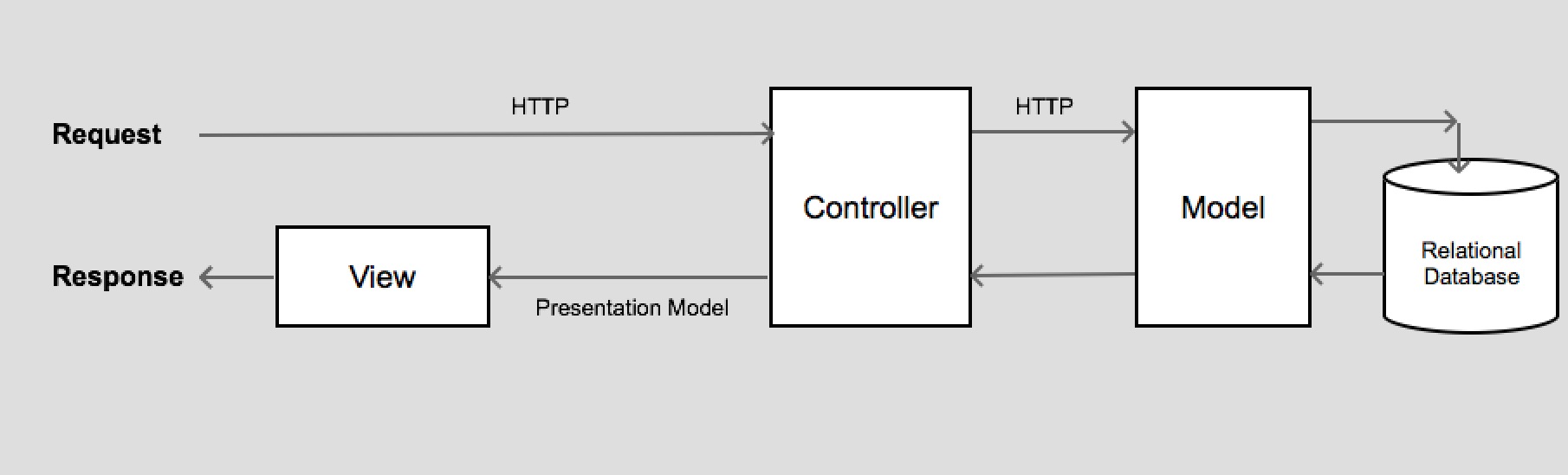
MVC in Angular
Here the MVC is on client side. In angular we have our view as html template where we have html component , view interact with controller, controller has all the ui business logic, it controls the data which is rendered on UI, the model is simple java script object which has bi-directional binding with ui component.
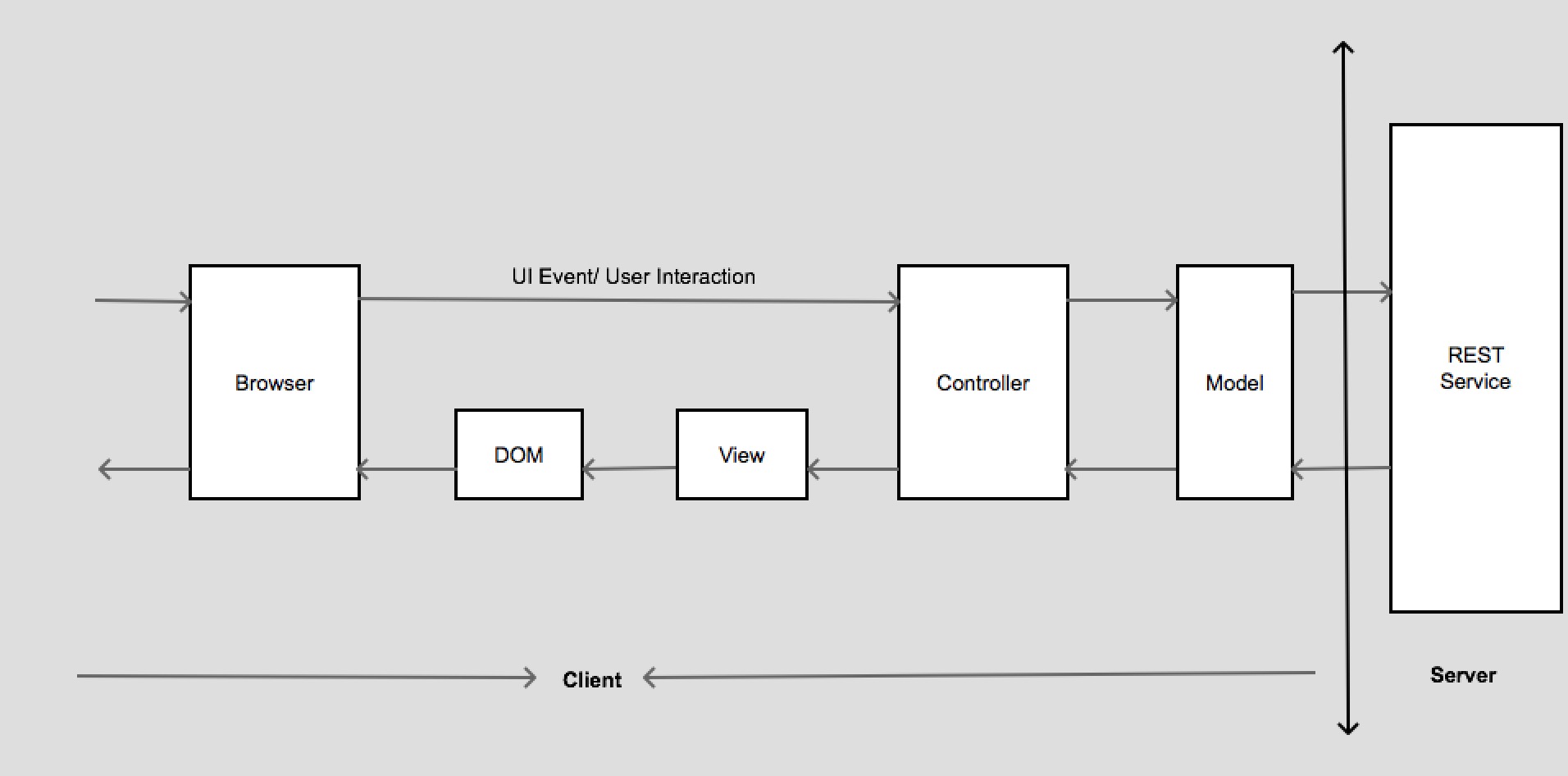
Important component of an AngularJS app
- Model:t is simple java script object and contains data which is shown to the user.
- View: View is HTM template which is rendered on UI. It may contain angular directive, expressions. The view is compiled and linked with the angular controller scope.
- Controller:The business logic that drives ur application.
- Scope:A context and simple java script object which contain data and functions. The data model and functions is set to the scope by controller.Set up the initial state of the $scope object.
- Directives:Something that we can add as HTML component. It extends HTML with custom elements and attributes.
- Filters:Selects a subset of items from array and returns it as a new array
- Resources: Used to communicate with server with http.
- Expressions:Expressions are represented by {{}} in the html and is used to access scope model and functions
Angular App Life Cycle
Lets create a simple Angular app to trace the lifecycle of Angular App
Create a HTML file -helloWorld.html and put below content
<!DOCTYPE html>
<html ng-app="exampleApp">
<head>
<title>Example</title>
<script src="vendor/angular/angular.min.js"></script>
<script src="app.js"></script>
</head>
<body ng-controller="helloWorldCtrl">
<div class="col-lg-4">
<div class="panel-body">
<input type="text" ng-model="name" placeholder="Your name">
<hr/>
<p>Welcome To Angular World:<strong> {{name}} </strong></p>
<button ng-click="logMe()">Show Log</button>
</div>
</div>
</body>
</html>
Create a file -app.js and put below content
angular.module("exampleApp", [])
.controller("helloWorldCtrl", function($log, $scope) {
$scope.name ='';
$scope.logMe = function(){
$log.log('Name Entered:: '+ $scope.name);
};
})
;
The above is simple Angular app with a module(exampleApp), a controller(helloWorldCtrl) and a simple view with some directives like ng-controller, ng-model etc.
Angular JS Life Cycle
How AngularJs Initializes the app (App bootstrapping)
<html ng-app=”exampleApp”> – The tag defines an ng-app directive attribute. Wherever Angular encounters this directive, it starts the initialization process. Since we have added ng-app to the tag, everything within the tag becomes part of our AngularJS app.
During this bootstrapping/initialization process Angular does the following:
- It loads the module for the application. Modules are containers for various Angular artifacts. Modules are a way for AngularJS to organize and segregate code.
- It sets up dependency injection (DI).
- It creates a $rootScope object, which is a scope object available at the global level and not tied to any specific HTML fragment.
- It compiles the DOM starting from where ng-app is declared. In this compilation process, the framework traverses the DOM, looks for all directives and interpolations {{}}, and sets up the binding between the view and model.
- Post compilation, it links the view and scope to produce a live view where changes are synced across the model and viewed in real time as we interact with the app.
$rootScope and $scope are instances of the same class (a constructor function). The difference is just the context in which they are available. $rootScope is available throughout the HTML (within ng-app) whereas $scope is always scoped by a specific HTML element.
This compilation and linking process can also lead to the creation of new scopes, all of which depend on the directive that is being applied to the HTML node.
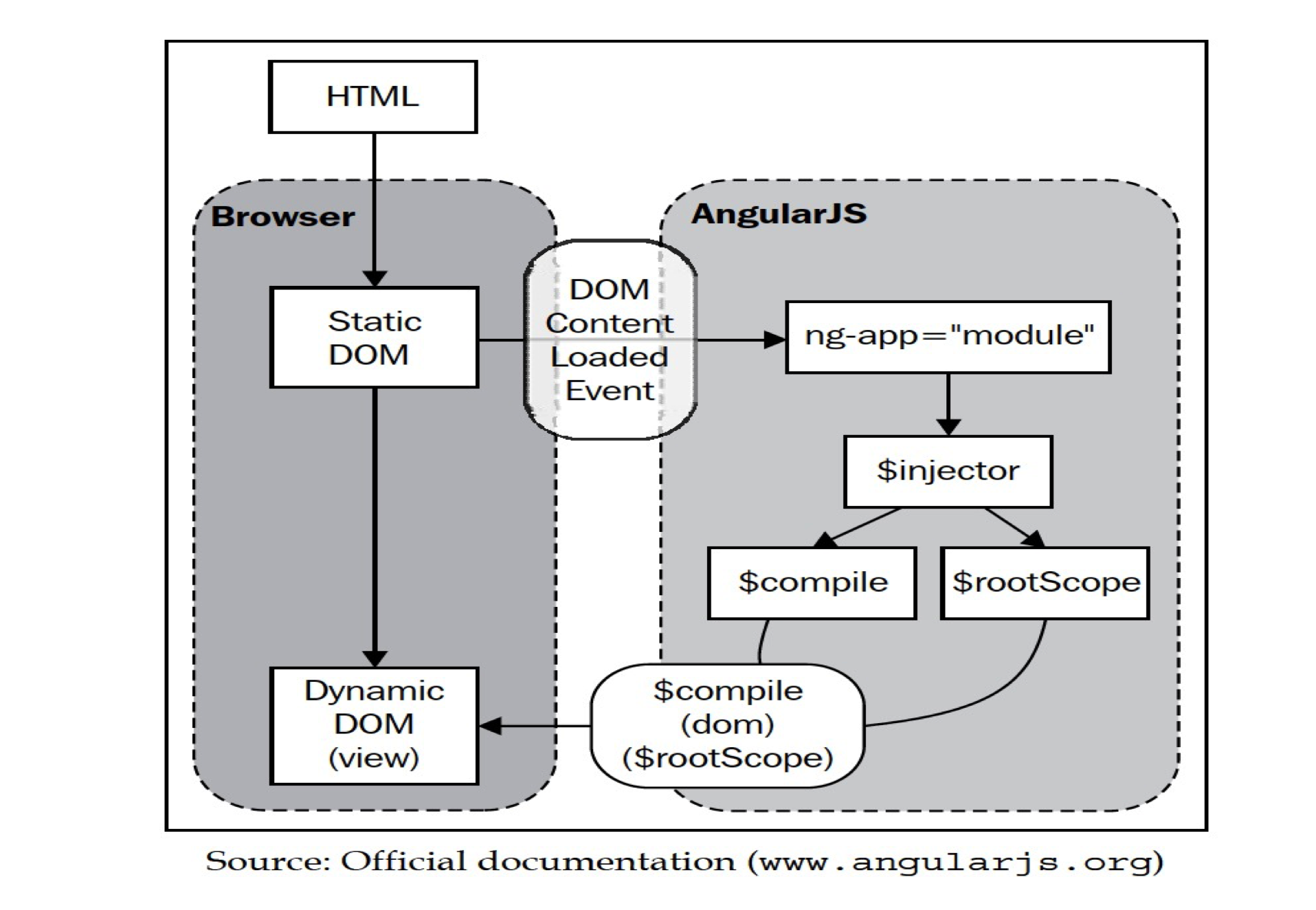
What is $scope
- Scopes are a core fundamental of any Angular app.
- The $scope object is where we define the business functionality of the application, the methods in our controllers, and properties in the views.
- This $scope object is a plain old JavaScript object. We can add and change properties on the $scope object.
- All properties found on the $scope object are automatically accessible to the view.
- Scope is the glue between Controller and View. Through $scope our Controller and View share data.
Every AngularJS application has at least one scope called $rootScope. This is created when we attach the ng-app directive to the HTML element. In other words you can say that during bootstrapping AngularJS create a $rootScope for your application.
When you attach ng-controller to any element of html, it creates a new child scope, which inherits from $rootScope. Child scope will have access to all the properties attached to parent scope.

What Can $scope Do?
Scopes have the following basic functions:
- They provide observers to watch for model changes.
- They provide the ability to propagate model changes through the application.
- They can be nested such that they can isolate functionality and model properties.
- They provide an execution environment in which expressions are evaluated.
- You can think of scopes as view models or presentation model.
What is Data Binding?
Data binding is the automatic synchronisation of data between View and the Model. When we say bi-directional binding, it mean that if something changes to model it will be reflect to View and if something changes to View it will be reflect to Model. As we have seen, we create model and set them on the $scope object. Then we tie out UI components with these model through expression {{}} or ng-model. This establishes a two-way binding between View component and model data.
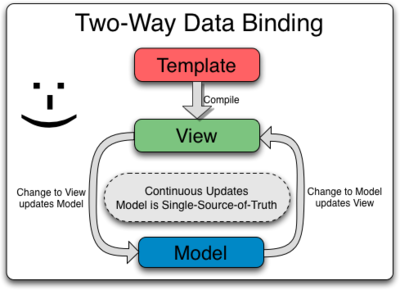
Watchers, $apply() and digest
When you write <input type=“text” ng-model=“name” /> the below steps happen :
- The directive ng-model registers a keydown listener with the input field. When the field text changes a keydown event is fired and the corresponding listener is called to handle it.
- Inside the keydown listener the directive assigns the new value of input field to the scope model specified in ng-model. In this case the name is updated with the new value. This code is wrapped inside$apply call.
- After $apply ends the digest cycle starts in which the watchers are called. If you have an expression {{name}} in the view it has already set up a watcher on scope model name. In the digest cycle the watchers gets called and the listener function executes with the newValue and oldValue as arguments. The job of this listener is to update the DOM with the newValue property using innerHTML.
- The result you see the {{name}} updated with whatever you type into the input field instantly.
Watcher Example – I: Lets put a simple watcher to the controller- Add below code to the ‘watcher.html’
<!DOCTYPE html>
<html ng-app="exampleApp">
<head>
<title>Example</title>
<script src="vendor/angular/angular.min.js"></script>
<script src="app.js"></script>
</head>
<body ng-controller="helloWorldCtrl">
<div class="col-lg-4">
<div class="panel-body">
<input type="text" ng-model="name" placeholder="Your name">
<hr/>
<p>Welcome To Angular World:<strong> {{name}} </strong></p>
<button ng-click="logMe()">Show Log</button>
</div>
</div>
</body>
</html>
Create a file ‘app.js’ and put below code
angular.module("exampleApp", [])
.controller("helloWorldCtrl", function($log, $scope) {
$scope.logMe = function(){
$log.log('Name Entered:: '+ $scope.name);
};
$scope.$watch(function(){
$log.log('called in a digest cycle::: '+$scope.name);
return;
});
})
;
Here we have watcher on scope, means it will be called when any scope model will be changed. Run the ‘watcher.html’ and enter some text to name field-
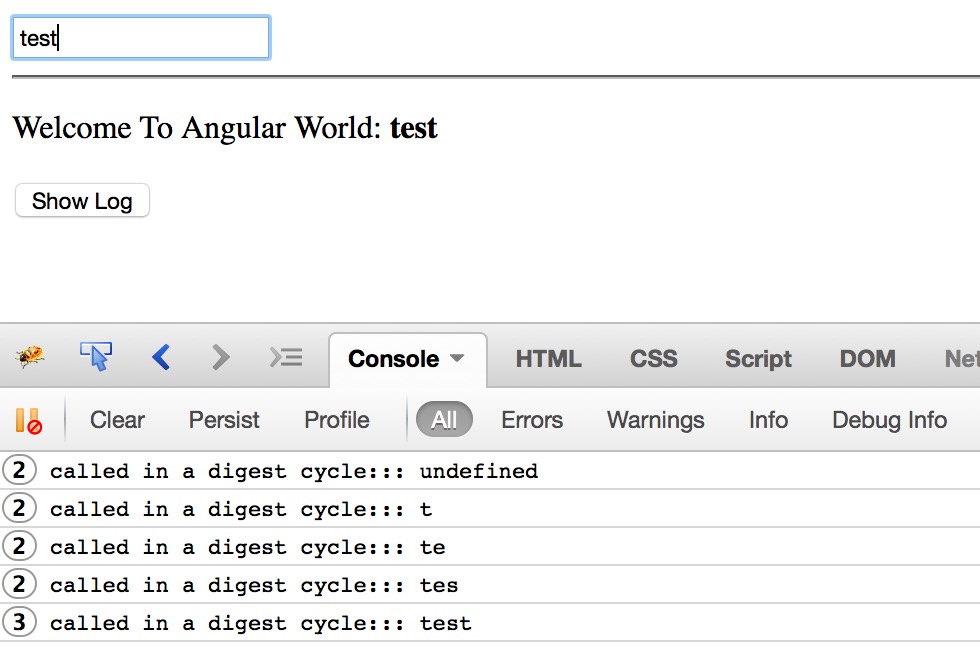
Here you can see – on the page load the digest cycle called 2 time, and on each character type it is called two times.
At the minimum the $digest() runs twice even if there are no model changes in the listener functions. The cycle runs once more to make sure the models are stable and no change has been made in the last loop, and this is called dirty checking.
Watcher Example – II: Add watcher to specific field- Add below code to the ‘watcher.html’
<!DOCTYPE html>
<html ng-app="exampleApp">
<head>
<title>Example</title>
<script src="vendor/angular/angular.min.js"></script>
<script src="app.js"></script>
</head>
<body ng-controller="helloWorldCtrl">
<div class="col-lg-4">
<div class="panel-body">
<input type="text" ng-model="name" placeholder="Your name">
<hr/>
<p>Welcome To Angular World:<strong> {{name}} </strong></p>
<button ng-click="logMe()">Show Log</button>
</div>
</div>
</body>
</html>
Add below code to ‘app.js’ –
angular.module("exampleApp", [])
.controller("helloWorldCtrl", function($log, $scope) {
$scope.name='';
$scope.logMe = function(){
$log.log('Name Entered:: '+ $scope.name);
};
$scope.$watch('name', function(newValue , oldValue){
$log.log('called in a digest cycle:::');
$log.log('old value: '+oldValue +' New Value: '+newValue);
return;
});
})
;
Run the ‘watcher.html’ –
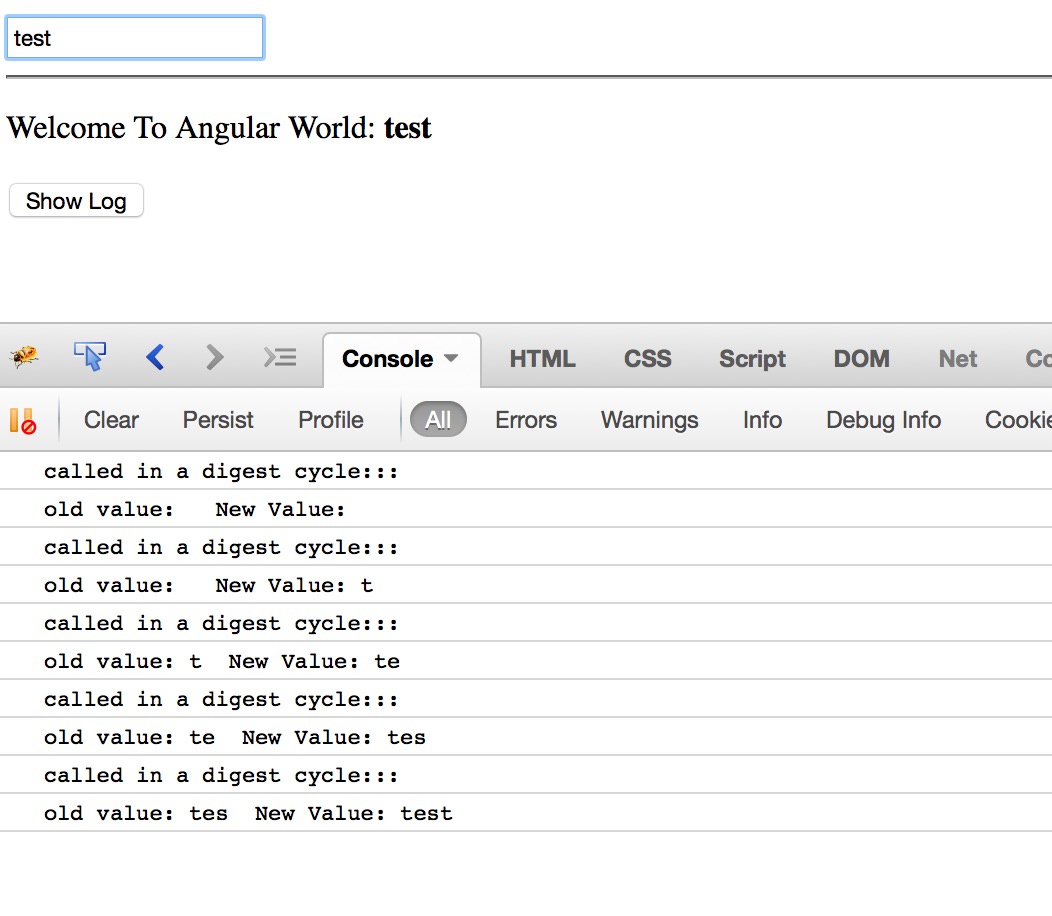
Here you can see – on the page load the digest cycle called and initially oldValue and newValue are blank.As soon as you type first character the newValue becomes ‘t’ and oldValue is still blank, when you type second character the oldValue becomes ‘t’ and newValue = ‘te’ and so on.
How does Angular know when a model changes and calls its corresponding watchers?
- An Angular $scope has a function called $apply() which takes a function as an argument.
- AngularJS says that it will know about model mutation only if that mutation is done inside $apply(). So you simply need to put the code that changes models inside a function and call $scope.apply(), passing that function as an argument.
- After the $apply() function call ends, AngularJS knows that some model changes might have occurred. It then starts a digest cycle by calling another function —- $rootScope.$digest() — which propagates to all child scopes.
- In the digest cycle watchers are called to check if the model value has changed. if a value has changed, the corresponding listener function then gets called. Now it’s up to the listener how it handles the model changes.
- The watchers set up by an expression ({{}}) updates the DOM with the new value of the model.
What if the listener function of the watcher itself changes any model?
Let’s see what happen with the help of an example-
Watcher Example – III: Change model inside watcher- Add below code to the ‘watcher.html’
<!DOCTYPE html>
<html ng-app="exampleApp">
<head>
<title>Example</title>
<script src="vendor/angular/angular.min.js"></script>
<script src="app.js"></script>
</head>
<body ng-controller="helloWorldCtrl">
<div class="col-lg-4">
<div class="panel-body">
<input type="text" ng-model="name" placeholder="Your name">
<hr/>
<p>Welcome To Angular World:<strong> {{name}} </strong></p>
<button ng-click="logMe()">Show Log</button>
</div>
</div>
</body>
</html>
Add below code to ‘app.js’ where we are changing the model inside watcher which will trigger watcher again and again–
//show digest limit
angular.module("exampleApp", [])
.controller("helloWorldCtrl", function($log, $scope) {
$scope.name='';
$scope.logMe = function(){
$log.log('Name Entered:: '+ $scope.name);
};
var count =0;
$scope.$watch('name', function(newValue , oldValue){
$log.log('called in a digest cycle:::');
$log.log('Old Value: '+oldValue +' New Value: '+newValue);
$scope.name = 'clicked'+(count++);//changing model
return;
});
})
;
Run the ‘watcher.html’
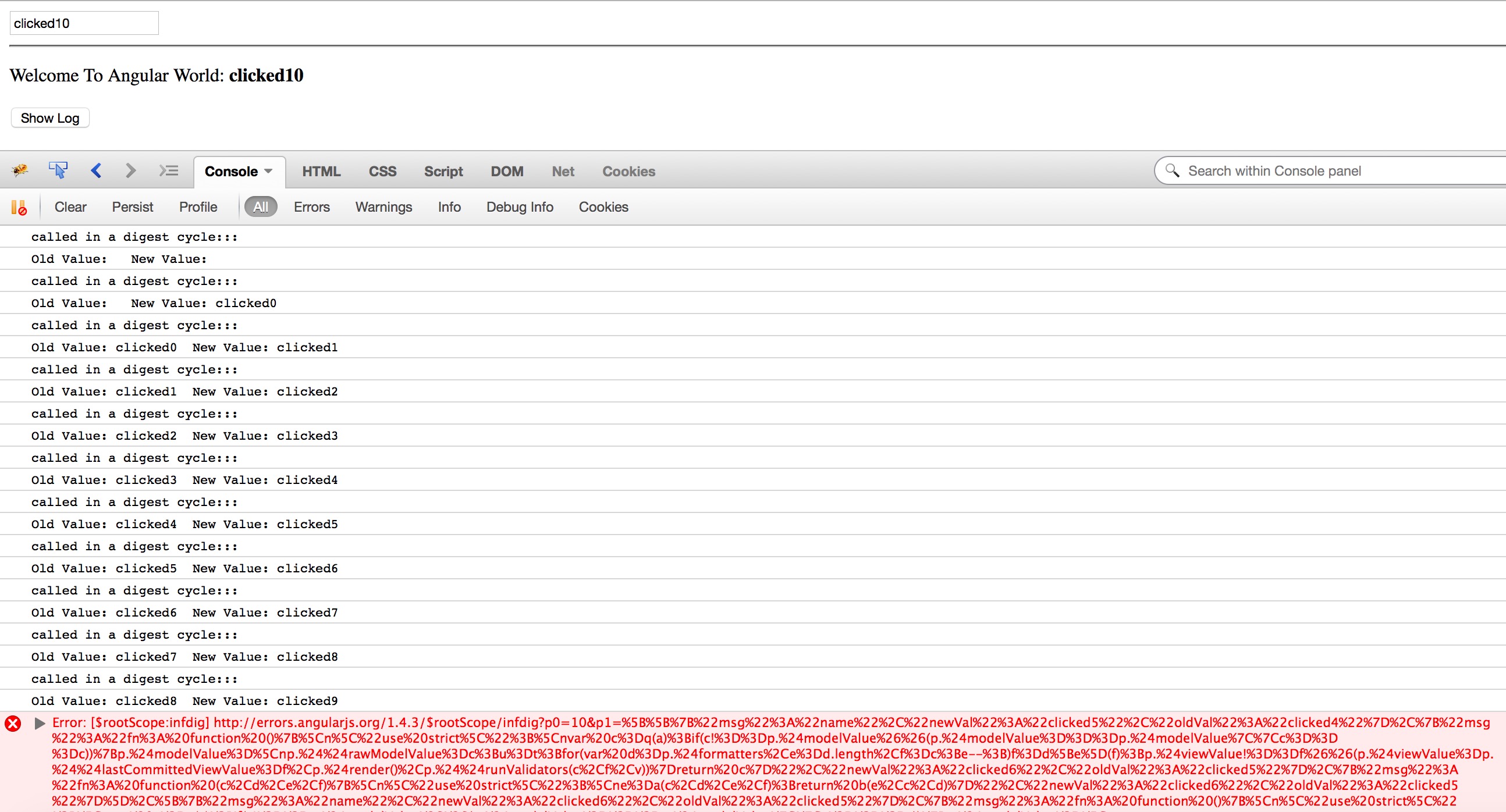
You can see that watcher is called only 10 times and after that it throws some kind of error.
As I have written earlier, the digest cycle doesn’t run only once after $apply() call. After calling the listener functions, the digest cycle start all over again and fires each watcher to check if any of the models have been mutated the last loop. If any changes is found, the corresponding listener is called as usual and, if none of the models have changed, the digest cycle ends. Otherwise the digest cycle continues to loop until no model changes have been detected or it hits the maximum loop count 10(whichever comes first). The digest cycle will not run more than 10 times. It’s a bad idea to making model mutation inside listener functions.
Using $apply()
Use $apply() when you want to say – Angular that I am mutating some model, and now it’s your job is to fire the watchers!”. Angular does it implicitly if you are changing a model to Angular world, you are not suppose to wrap model change inside $apply().
But if you are mutating some model outside angular world then you will have to wrap the model changes inside $apply() call explicitly.
Consider Below example –
Example – Changing model outside Angular world:
Create a file ‘apply.html’ and put below code –
<!DOCTYPE html>
<html ng-app="exampleApp">
<head>
<title>Example</title>
<script src="vendor/angular/angular.min.js"></script>
<script src="app.js"></script>
</head>
<body ng-controller="helloWorldCtrl">
<div class="col-lg-4">
<div class="panel-body">
<button ng-click="scheduleTask()">Get Message after 3 seconds</button>
<br/>Message fetched: {{message}}
</div>
</div>
</body>
</html>
Create a file ‘app.js’ and put below code –
angular.module("exampleApp", [])
.controller("helloWorldCtrl", function($log, $scope) {
$scope.logMe = function(){
$log.log('Name Entered:: '+ $scope.name);
};
//ng-click trigger, watcher will not be called
$scope.scheduleTask = function() {
setTimeout(function() { //out side angular scope
$scope.message = 'Fetched after 3 seconds'; // model mutation
$log.log('message='+$scope.message); //log this to console
}, 3000);
};
$scope.$watch('message', function(newValue , oldValue){
$log.log('called in a digest cycle:::');
$log.log('Old Value: '+oldValue +' New Value: '+newValue);
return;
});
})
;
Run the html –
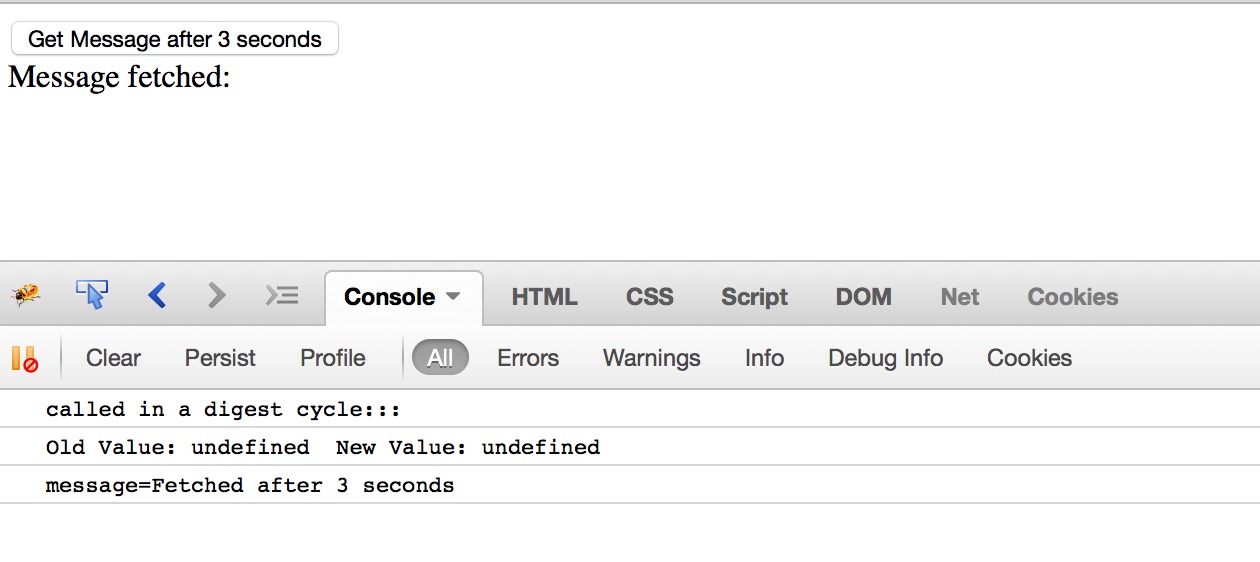
You can see that the digest cycle only called on page load. When I click the button, the ‘scheduleTask()’ method called which mutate the model message, but the digest cycle doesn’t get called, because I am mutating that outside of Angular world inside timeout.
If you want to watcher to be called then put the model mutation code inside $apply() – Change your ‘app.js’ like below-
angular.module("exampleApp", [])
.controller("helloWorldCtrl", function($log, $scope) {
$scope.logMe = function(){
$log.log('Name Entered:: '+ $scope.name);
};
//digest cycle will triggered
$scope.scheduleTask = function() {
setTimeout(function() {
$scope.$apply(function() { // wrapped the code in $apply()
$scope.message = 'Fetched after 3 seconds';
});
$log.log('message='+$scope.message); //log this to console
}, 3000);
};
$scope.$watch('message', function(newValue , oldValue){
$log.log('called in a digest cycle:::');
$log.log('Old Value: '+oldValue +' New Value: '+newValue);
return;
});
})
;
Run the html –
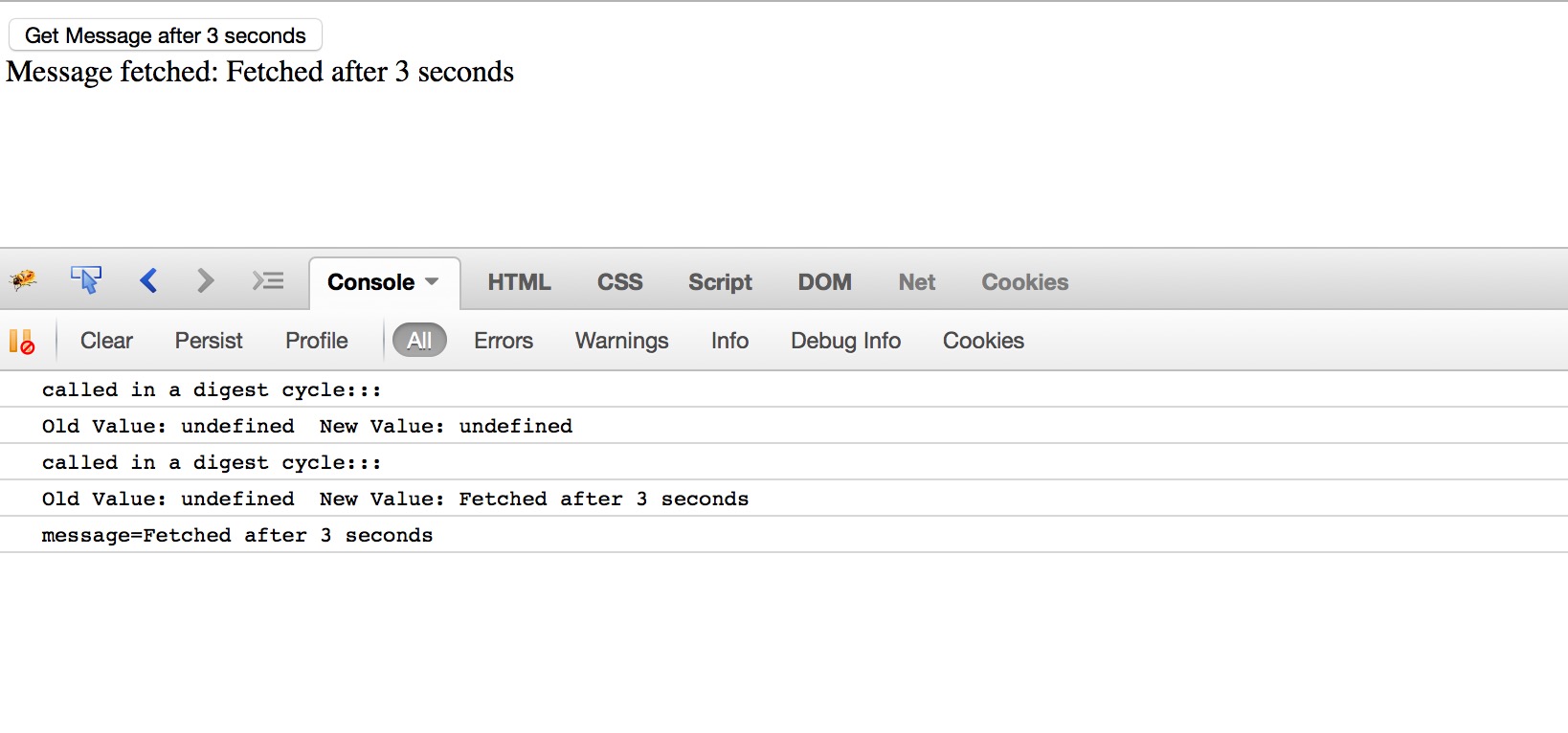
Now you can see, $digest cycle is called.
That is for now – In my next section I am going to write about $filter, custom directive, routing and resources for http request.
References
ANGULAR JS Novice to Ninja – Sandeep Panda
ng-book The Complete book on AngularJs – Ari Lerner
Pro Angular JS – Adam Freeman